本地安装部署运行 ChatGLM-6B 的常见问题解答以及后续优化
不敢称之为教程,只能算是分享一点自己本地安装部署运行 ChatGLM-6B 的过程中的心得和二次优化开发吧。主要是比如怎么防止GPU运行时爆显存,GPU运行时减少显存占用,一些常见的报错应该怎么解决,推理参数的调整方案,怎么开启局域网访问,怎么给网页加上HTTPS。ChatGLM2-6B 的常见问题和ChatGLM-6B基本一致,以下无特殊说明的说明对两者都是通用。
- ChatGLM-6B 系列文章之一:使用 CPU 本地安装部署运行 ChatGLM-6B 获得自己的专属 AI 猫娘
- ChatGLM-6B 系列文章之二:本地安装部署运行 ChatGLM-6B 的常见问题以及后续优化
- ChatGLM-6B 系列文章之三:ChatGLM2-6B 更强大的新一代的GLM模型
-
其他AI相关:其他AI相关
[toc]
ChatGLM-6B 常见报错及解决方案
报错 No module named ‘transformers_modules.THUDM/chatglm-6b’
报错本身的意思是,没有在指定的路径THUDM/chatglm-6b找到推理用模型
一般常见于自己手动下载模型,而不是通过下边这些文件直接启动,自动下载的情况
你需要修改web_demo.py,web_demo.py,old_web_demo2.py,cli_demo.py,api.py等文件中涉及模型路径部分的代码,一般在文件的开头或者结尾附近。
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
将里面的"THUDM/chatglm-6b"改成实际模型存放路径名称即可
注意win系统下子文件夹的路径应该写成\("THUDM\chatglm-6b"), 原代码写的是linux文件系统用的/ ("THUDM/chatglm-6b")。
报错 not enough memory: you tried to allocate 123456789 bytes.
内存不足,显存不足,最简单就是换个更好的电脑吧,或者看后面ChatGLM-6B 减少显存与内存占用部分内容。
报错 AssertionError: Torch not compiled with CUDA enabled
原因是 你试图用GPU跑,但是你安装的 Torch 不支持CUDA,是仅支持CPU的版本
先执行命令:
python -c "import torch; print(torch.cuda.is_available())"
如果返回的是False,说明安装的PyTorch不支持CUDA,是仅支持CPU的,需要执行了下面的命令安装支持cuda的版本:
pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 -f https://download.pytorch.org/whl/cu117/torch_stable.html
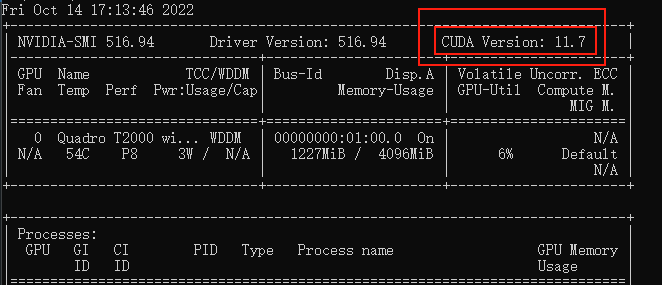
其中里面的3处 cu117 需要根据你自己的CUDA版本修改
命令行执行nvidia-smi,命令,看下自己显卡支持的 CUDA版本(比如我这里是11.7)
报错 RuntimeError: Library XXXXXX is not initialized
这个报错直接就是需要的XXXXX文件没找到
如果你只是跑模型demo的话,这个提示一般都是显存或内存不够导致的。
也有可能是因为python的环境变量没有写入系统,CUDA没正确安装,显卡驱动没正确安装等原因。
减少内存占用可以参考下方的 ChatGLM-6B 减少显存与内存占用
ChatGLM-6B 减少显存与内存占用
全量模型运行加载 GPU运行模式下需要13GB显存+14G内存,CPU运行模式下需要28GB内存,如果你电脑没这么大显存或者内存,可以通过加载量化模型减少显存与内存占用
ChatGLM-6B 加载量化模型
加载量化模型运行,其实就是个用性能的下降换硬件配置需求的下降,量化模型的质量会低于全量模型,视GPU或CPU型号,对in4,int8,FP16量化的性能可能有较大差异。ChatGLM-6B 在 4-bit 量化下仍然能够进行还算可以的生成。
本地将全量模型转化为量化模型加载
优点嘛,你只需要下载一个全量模型,就可以自己选加载全量,INT4还是INT8
缺点是,量化过程需要在内存中首先加载 FP16 格式的模型,会消耗大概 13GB 的内存。
你电脑要是16GB内存,可能就不能同时运行太多其他程序了
你需要修改web_demo.py,web_demo.py,old_web_demo2.py,cli_demo.py,api.py等文件中涉及模型部分的代码,一般在文件的开头或者结尾附近。(你需要那个文件就改哪个文件,不需要全改)
#原始代码
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
#INT4量化 显卡GPU加载
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(4).half().cuda()
- 全量模型多轮对话后,大概需要14~15GB显存,IN8多轮对话后大概需要10GB显存,INT4多轮对话后大概需要6~7G显存
- 量化过程需要在内存中首先加载 FP16 格式的模型,消耗大概 13GB 的内存。如果你的内存不足的话,可以看下一步直接加载量化后的模型
直接加载量化模型
如果你电脑内存实在捉襟见肘的话,可以选择直接使用现成的INT4量化模型,这样内存中只需要占用5.5GB左右了,使用GPU运行时,8G内存的电脑也可以一战了,使用CPU运行时,可以允许24GB甚至16GB内存的电脑运行,显著降低运行配置。
CPU运行量化模型需要安装GCC与openmp,多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp(你不一定非要用TDM-GCC,用MinGW-w64也可以的,主要是记得装openmp)。
#下载模型放在chatglm-6b-int4文件夹内
git clone -b int4 https://huggingface.co/THUDM/chatglm-6b.git chatglm-6b-int4
然后修改相关代码
你需要修改web_demo.py,web_demo.py,old_web_demo2.py,cli_demo.py,api.py等文件中涉及模型部分的代码,一般在文件的开头或者结尾附近。(你需要哪个文件就改那个文件,不需要全改)
#原始代码
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
#INT4量化 显卡GPU加载
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b-int4", trust_remote_code=True).quantize(4).half().cuda()
#INT4量化 处理器CPU加载
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b-int4",trust_remote_code=True).float()
注意这里我改了"THUDM/chatglm-6b"是因为我上边下载INT4的命令,指定下载到chatglm-6b-int4文件夹中,如果你改动了代码,请根据你自己的实际情况修改对应部分。
ChatGLM-6B 优化多轮对话后的内存/显存占用大,解决爆显存问题
通过修改代码,减少多轮后的返回对话数量,简单粗暴的解决问题,下边以web_demo_old.py为例,其他文件可以参照修改。
升级到ChatGLM2-6B
ChatGLM2-6B 做了优化,原来 ChatGLM-6B 在 int4 量化,8G 显存下对话长度在 1K 左右及有可能爆显存,ChatGLM2-6B 基本可以对话长度达到 8K 时才爆掉。
修改代码,只保留最近3~4轮对话的内容
很简单粗暴的方式,不然有时候,很容易在进行到5~6轮对话就炸显存了
from transformers import AutoModel, AutoTokenizer
import gradio as gr
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
MAX_TURNS = 20
MAX_BOXES = MAX_TURNS * 2
def predict(input, max_length, top_p, temperature, history=None):
if history is None:
history = []
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
temperature=temperature):
updates = []
for query, response in history:
updates.append(gr.update(visible=True, value="用户:" + query))
updates.append(gr.update(visible=True, value="ChatGLM-6B:" + response))
if len(updates) < MAX_BOXES:
updates = updates + [gr.Textbox.update(visible=False)] * (MAX_BOXES - len(updates))
yield [history] + updates
原始代码如上,请把第15行修改为这样的
for response, history in model.stream_chat(tokenizer, input, max_length=max_length, top_p=top_p, temperature=temperature, history=(history if len(history) <= 3 else history[-3:])):
- 历史对话轮数小于等于3(
<= 3)那么直接返回history的内容 - 否则返回最后3轮的内容(
history[-3:]) - 如有需要请自己改这两个数字
修改代码,只保留第一条,第二条,以及最近3轮对话
很多本地部署用户都有将 ChatGLM-6B 先设定人设,进而接入vits、智能音响、物联网设备等,而第一句话和第二句话通常用于树立和补充人设/猫设,是非常重要的,需要保留。
from transformers import AutoModel, AutoTokenizer
import gradio as gr
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).float()
model = model.eval()
MAX_TURNS = 20
MAX_BOXES = MAX_TURNS * 2
first_ans = ('','')
second_ans = ('','')
def predict(input, max_length, top_p, temperature, history=None):
global first_ans
global second_ans
if history is None:
history = []
for response, history in model.stream_chat(tokenizer, input, max_length=max_length, top_p=top_p,
temperature=temperature, history=(history if len(history) <= 4 else [first_ans] + [second_ans] + history[-3:])):
if len(history) <= 1 :
first_ans = history[0]
if len(history) <= 2 and len(history) > 1 :
second_ans = history[1]
updates = []
for query, response in history:
updates.append(gr.update(visible=True, value="用户:" + query))
updates.append(gr.update(visible=True, value="ChatGLM-6B:" + response))
if len(updates) < MAX_BOXES:
updates = updates + [gr.Textbox.update(visible=False)] * (MAX_BOXES - len(updates))
yield [history] + updates
- 第11和第12行为新增,意思是:搞一个分别名为first_ans与second_ans的全局变量,并把他们置空
- 第15和第16行为新增,意思是:在函数内部声明first_ans与second_ans这两个全局变量,这样才能在函数predict中对它们进行修改,并且在函数外部也可以使用修改后的值。
- 第20行为对原始代码第15行的修改,意思是:
- 如果对话轮数小于等于4轮(
<= 4),那么直接返回history的内容 - 如果对话轮数大于4轮,那么将first_ans储存的第一句对话和second_ans储存的第二轮对话,拼接在最后3轮对话(
history[-3:])前返回给history
- 如果对话轮数小于等于4轮(
- 第21~24行为新增,意思是:判断对话轮数,在正确的轮数,保存对应的对话在全局变量first_ans和second_ans中。
ChatGLM-6B 减少多轮对话后的复读
根据作者在#43的回复
可以给 chat 或者 stream_chat 接口传入 repetition_penalty 参数,将参数设置为一个大于1的浮点数来解决复读问题。这里以web_demo.py为例,给出原始代码块,和修改后的代码块,参照修改即可。
- 在stream_chat 接口传入 repetition_penalty 参数
#原始代码段01开始
def predict(input, chatbot, max_length, top_p, temperature, history, past_key_values):
chatbot.append((parse_text(input), ""))
for response, history, past_key_values in model.stream_chat(tokenizer, input, history, past_key_values=past_key_values,
return_past_key_values=True,
max_length=max_length, top_p=top_p,
temperature=temperature):
chatbot[-1] = (parse_text(input), parse_text(response))
#原始代码段01结束
#修改代码段01开始
def predict(input, chatbot, max_length, top_p, temperature, history, past_key_values, repetition_penalty):
chatbot.append((parse_text(input), ""))
for response, history, past_key_values in model.stream_chat(tokenizer, input, history, past_key_values=past_key_values,
return_past_key_values=True,
max_length=max_length, top_p=top_p,
temperature=temperature, repetition_penalty=repetition_penalty):
chatbot[-1] = (parse_text(input), parse_text(response))
#修改代码段01结束
#原始代码段02开始
submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history, past_key_values, repetition_penalty],
[chatbot, history, past_key_values], show_progress=True)
submitBtn.click(reset_user_input, [], [user_input])
#原始代码段02结束
#修改代码段02开始
submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history, past_key_values],
[chatbot, history, past_key_values], show_progress=True)
submitBtn.click(reset_user_input, [], [user_input])
#修改代码段02结束
- 给网页demo增加调整Repetition Penalty参数的输入框,并设定默认值为1
#原始代码段03开始
with gr.Column(scale=1):
emptyBtn = gr.Button("Clear History")
max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)
top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
#原始代码段03结束
#修改代码段03开始
with gr.Column(scale=1):
emptyBtn = gr.Button("Clear History")
max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)
top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
repetition_penalty = gr.Slider(0, 2, value=1.0, step=0.1, label="Repetition Penalty", interactive=True)
#修改代码段03结束
ChatGLM-6B 的推理参数含义
Maximum length 参数
通常用于限制输入序列的最大长度,因为 ChatGLM-6B 是2K长度推理的(ChatGLM2-6M 是32K长度训练,8K对话训练),一般这个保持默认就行。
太大可能会导致性能下降
Top P 参数
Top P 参数是指在生成文本等任务中,选择可能性最高的前P个词的概率累加和。这个参数被称为Top P,也称为Nucleus Sampling。简单理解这个就是镇定剂,数值越低AI越冷静,质量越高,但也越无趣。
例如,如果将Top P参数设置为0.7,那么模型会选择可能性排名超过70%的词进行采样。这样可以保证生成的文本更多样,但可能会缺乏准确性。相反,如果将Top P参数设置为0.3,则会选择可能性前30%的词进行采样,这会导致生成文本的准确性提升,但能够减少多样性。
Temperature 参数
Temperature参数通常用于调整softmax函数的输出,用于增加或减少模型对不同类别的置信度。
具体来说,softmax函数将模型对每个类别的预测转换为概率分布。Temperature参数可以看作是一个缩放因子,它可以增加或减少softmax函数输出中每个类别的置信度。
你可以理解为这是兴奋剂,值越大AI越兴奋。
比如将 Temperature 设置为 0.05 和 0.95 的主要区别在于,T=0.05 会使得模型更加冷静,更加倾向于选择概率最大的类别作为输出,而 T=0.95 会使得模型更加兴奋,更加倾向于输出多个类别的概率值较大。
Repetition Penalty 参数
这是个可以自己加的参数,主要是为了控制多轮对话后发生的复读上文问题。
= 1不惩罚重复,> 1时惩罚重复,< 1时鼓励重复。
一不要设置小于 0.5 ,小于 0.5 则极可能出现灾难级的复读。
一些本来就需要发生多次重复的任务也不适合设置过大的参数,比如你让模型写一篇关于XXX的报告。
那XXX这个名字本身就需要被多次重复提及。
ChatGLM-6B 其他设置
ChatGLM-6B 开启网页远程分享
可以让个人电脑部署的网页端,在互联网上也可以远程访问。
你需要修改web_demo.py,web_demo.py,old_web_demo2.py等文件中涉及网络部分的代码,一般在文件结尾附近。(你需要哪个文件就改那个文件,不需要全改)
一般类似于demo.queue().launch(share=False, inbrowser=True)
把share=False改成share=True
会得到一个 Gradio 服务器转发地址,就可以远程访问了,注意由于国内 Gradio 的网络访问较为缓慢,导致网页端的打字机体验大幅下降
ChatGLM-6B 开启局域网访问/开启公网访问
如果你的机器本身有公网,或者想在局域网内其他设备访问
你需要修改web_demo.py,web_demo.py,old_web_demo2.py等文件中涉及网络部分的代码,一般在文件结尾附近。(你需要哪个文件就改那个文件,不需要全改)
一般类似于demo.queue().launch(share=False, inbrowser=True)
修改为demo.queue().launch(share=False, inbrowser=True, server_name='0.0.0.0', server_port=8070)
这将在所有可用的网络端口开放8070端口号,并且不启用Gradio 服务器转发。
ChatGLM-6B 修改本地网页端口号
因为默认是127.0.0.1:7860嘛,可能会和其他本地程序冲突
你需要修改web_demo.py,web_demo.py,old_web_demo2.py等文件中涉及网络部分的代码,一般在文件结尾附近。(你需要哪个文件就改那个文件,不需要全改)
一般类似于demo.queue().launch(share=False, inbrowser=True)
修改为demo.queue().launch(share=False, inbrowser=True, port=7870)
这样端口就变成7870了。
目前正在做的调试
- [X] 开放局域网访问
- [X] 减少爆显存问题
- [X] 解决对话超过10~20轮后开始大量复读的问题
- 研究微调模型,自行输入知识库,比如搞个自己的对话克隆人?(右键→新建文件夹)

汪汪
2023-11-15 17:26
ChatGLM3已经出了,大佬能不能帮忙找个速度快的镜像站?模型下不动
汪汪
2023-11-15 19:24
已解决,用联通线路下的很快。
涂先生
2023-10-20 11:24
使用Linux 系统 部署 ChatGlm2-6b 微调成功之后 运行bash web_demo.sh 生成共享链接http://192.168.3.59:7870 链接在其它电脑上可以打开 但是 提问的时候无法回答 无响应是什么问题?
涂先生
2023-10-20 11:17
大神 我在Lunux 下部署了ChatGLM-6B 微调之后 运行base web_demo.sh 报
bash web_demo.sh
/home/kings/ChatGLM/ptuning/web_demo.py:101: GradioDeprecationWarning: The
stylemethod is deprecated. Please set these arguments in the constructor instead.user_input = gr.Textbox(show_label=False, placeholder=”Input…”, lines=10).style(
Loading prefix_encoder weight from output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-3000
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.46it/s]
Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /home/kings/ChatGLM and are newly initialized: [‘transformer.prefix_encoder.embedding.weight’]
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Running on local URL: http://192.168.3.59:7870
Could not create share link. Please check your internet connection or our status page: https://status.gradio.app.
分享共享链接 我用自己的mac 电脑连接liunx 服务器微调之后生成的地址http://192.168.3.59:7870 地址可以访问! 但是对话没有响应? 这是什么问题?
yx
2023-07-21 11:19
大神你好,我这边启动没有问题,但是在进行对话提交的时候就报错了:Library cuda is not initialized,不知道是什么原因
去年夏天
2023-07-21 11:26
这个报错直接就是需要的XXXXX文件没找到
如果你只是跑模型demo的话,这个提示一般都是显存或内存不够导致的。
也有可能是因为python的环境变量没有写入系统,CUDA没正确安装,显卡驱动没正确安装等原因。
需要一个一个排查,你这个看起来像是CUDA没正确安装的感觉,可以参考这个文章装一下CUDA
汪汪
2023-07-20 17:18
大佬,请教一个问题,有什么办法测试自己的服务器能跑到多少 token/s ?
Kevster
2023-07-18 17:24
大神您好,我在浏览器中输入 http://127.0.0.1:7860之后,开始与ChatGLM-6B进行对话时,会报错:Error Connection errored out。部署了但是无法对话。跟着大神ChatGLM2-6B的教程部署了这个版本之后,问答时也同样报错:Error Connection errored out。这个问题应该怎么解决呢?
去年夏天
2023-07-18 17:45
1、CMD窗口是否被关闭了,需要保持那个黑乎乎的CMD窗口存在。
2、浏览器或本地是否有代理工具,关闭代理工具试试。
Kevster
2023-07-19 09:42
CMD窗口一直是开启的。我不确定有没有代理,但至少本地部署stable diffusion webui之后,同样是浏览器访问http://127.0.0.1:7860,图片可以正确生成。
Kevster
2023-07-19 09:50
可能是与stable diffusion webui端口相同,才导致chatglm connection errored out吗,我尝试添加了一个port,但报错: demo.queue().launch(share=True, inbrowser=True, port=7870)
TypeError: Blocks.launch() got an unexpected keyword argument ‘port’
瑞思拜
2023-07-18 08:27
大神您好,我将chatglm2-6b部署在服务器,开放了api供多人访问,但是对同时对话5,6个的时候,glm的回答就非常非常慢了。如果不能增加显存,有什么优化的好办法没?
去年夏天
2023-07-18 08:58
考虑使用一下对 ChatGLM2 进行加速的开源项目:
瑞思拜
2023-07-18 09:02
Woo~您可太棒了,我会在各大平台都关注您的谢谢!
汪汪
2023-07-20 16:47
我觉得这个问题完全可以用钞能力解决啊。我在四五线小城市建服务器并且维护,我把服务器共享给你,你只要机时费就可以了。
xiaotaiyyy
2023-07-08 17:11
大神好,我的chatglm是部署在服务器上的,修改代码为demo.queue().launch(share=True, inbrowser=True,server_name= “0.0.0.0”,server_port= 22227),但在http://0.0.0.0:22227/显示无法访问此网站,网页可能暂时无法连接,或者它已永久性地移动到了新网址,这是什么原因啊
去年夏天
2023-07-08 20:29
要访问服务器IP才对
http://服务器IP:22227年糕
2023-07-03 23:00
12700核显,32内存,没独显。 对话很慢。 需要加显卡,还是怎么做,能提升 回答速度
毕凡
2023-06-13 08:14
为什么对话不了呢大佬按发送信息没有反应
去年夏天
2023-06-13 08:36
控制台那边有什么提示吗?
LL
2023-06-09 15:26
您好,报错ChatGLM-6B/chatglm-6b is not a local folder and is not a valid model identifier listed on ‘https://huggingface.co/models’
If this is a private repository, make sure to pass a token having permission to this repo with
use_auth_tokenor log in withhuggingface-cli loginand passuse_auth_token=True.这个要怎么解决呢去年夏天
2023-06-10 09:36
只从报错看,应该是没找到ChatGLM-6B/chatglm-6b这个文件夹,检查一下所运行的代码,看下模型路径部分写对了吗?
111
2023-06-07 11:43
你好,请问我在运行python web_demo 的时候出现AttributeError: ‘NoneType’ object has no attribute ‘int4WeightExtractionHalf’,这个怎么解决呢?
hitvz
2023-07-04 23:56
我也遇到了。应该是int4类型的模型不支持mps类型的运行导致的或者half()方法不支持,改成只有float()运行。
model = AutoModel.from_pretrained(“/你的具体路径/chatglm2-6b-int4”, trust_remote_code=True).float()
ai小白鼠
2023-06-02 16:13
大佬,请问一下,我是6b的模型,在216G的显卡上训练的时候报显存溢出,我升级成232G的GPU之后还是报显存溢出。per_device_train_batch_size已经调整成1了,16G显卡上运行的时候报一共需要5个多G,32G的时候给我报需要22个G的显存? 想请教一下
ai小白鼠
2023-06-03 09:47
上面的描述应该是2×16G 和2×32G
汪汪
2023-06-01 22:27
大佬,请教一下,chatglm原版带的html代码如何去除?
如下:
写一篇推销钻石的广告
以下是一篇推销钻石的广告:标题:闪耀你的美丽钻石,是一种永恒的美丽。它们不仅代表着珍贵和财富,更代表着爱情和承诺。在这个情人节和七夕节的时刻,我们想要向你展示如何闪耀你的美丽。我们的钻石是最优质的,从天然钻石到合成钻石,我们都有。我们选择最好的钻石,因为它们代表着珍贵和美丽。我们也有最时尚的钻石珠宝,适合各种场合。如果你正在寻找一个爱情的象征,我们的钻石将是你的最佳选择。它们不仅闪耀着独特的光芒,更代表着珍贵和承诺。在这个特别的时刻,让你的爱钻石闪耀吧!现在就来我们的店铺,让我们的钻石闪耀你的美丽。
汪汪
2023-06-01 22:31
是这样的<p><br>,粘贴到回复就没了
汪汪
2023-05-31 11:35
大佬,我目前遇到一个难题。我在16G内存和一张1660S的电脑上运行int4正常,取掉一根8G内存就提示内存不足了。有什么办法能让8G内存的电脑正常运行int4和int8 ?
去年夏天
2023-05-31 14:10
因为模型需要先加载到内存,再复写到显存,直接使用现成的INT4量化模型试试,模型本体应该只需要5.5GB内存,如果还是炸内存官方框架内就没什么解决办法了。
汪汪
2023-06-01 22:34
8G内存再加16G虚拟内存,可以运行int8,不能运行int4,原因不明,反正是能跑起来了。
画枕
2023-05-29 12:34
博主好啊,我部署的chatglm-6b,开启share=True,跑python web_demo.py后互联网能访问到。我想用chatglm给我总结互联网网页内容,给它URL后,总是响应无法访问。不知博主知道是哪里的问题吗?
去年夏天
2023-05-29 17:26
chatglm原生并没有支持检索互联网功能吧
汪汪
2023-05-28 22:29
model = AutoModel.from_pretrained(“chatglm-6b-int4”, trust_remote_code=True).quantize(4).half().cuda()
大佬您好,我对上面“直接加载量化”这一段有点疑问,我记得官方教程好像是说,前面用了”chatglm-6b-int4″模型之后,后面的quantize(4)就不能加了。
如果您的写法是对的,多卡部署想加quantize(4)要怎么加?
from utils import load_model_on_gpus
model = load_model_on_gpus(“THUDM/chatglm-6b”, num_gpus=2)
绯雨
2023-05-19 02:52
大佬看看这个毛病啥啊,第二次部署的时候一直报这个错
FileNotFoundError: [WinError 2] 系统找不到指定的文件。: ‘C:\Users\Administrator.MIKU-2021KHUPJO\AppData\Local\Microsoft\WindowsApps’
去年夏天
2023-05-19 08:53
这。。我也搞不懂,WindowsApps文件夹应该是从win应用商店里下载安装的一些软件的启动位置,应该和chatglm没什么关系的
liuhantao
2023-04-17 10:52
报错 No module named ‘transformers_modules.THUDM/chatglm-6b’
4.26.1 可以正常使用,升级4.27.1以及以上版本不可用,并报如上错误
解决办法补充: “THUDM/chatglm-6b” 修改为”THUDM\chatglm-6b”
去年夏天
2023-04-17 10:55
谢谢提醒,他这个地方是比较坑,他代码写的是linux的写法/,win系统下应该是\。
liuhantao
2023-04-14 16:35
大神您好,我在部署ChatGLM-6B遇到的问题是,我的显卡是48GB显存的,但目前只能使用20GB显存(进行再多的会话也就使用到20GB显存),使用过程不爆显存,不知道我在哪里可以优化,让程序更多的使用显存?