使用 CPU 本地安装部署运行 ChatGLM-6B 获得自己的专属 AI 猫娘
ChatGLM-6B 是一个清华开源的、支持中英双语的对话语言模型,基于GLM架构,具有62亿参数。结合模型量化技术,ChatGLM-6B可以本地安装部署运行在消费级的显卡上做模型的推理和训练(全量仅需14GB显存,INT4 量化级别下最低只需 6GB 显存)虽然智商比不过 openAI 的 ChatGPT 模型,但是ChatGLM-6B 是个在部署后可以完全本地运行,可以自己随意调参,几乎没有任何审查限制,也几乎没有对话轮数限制的模型。ChatGLM-6B 模型用来调教成猫娘,魅魔什么的再合适不过了。
更新: ChatGLM2-6B 发布,支持32K长输入,8K对话记忆,同显存占用下可连续对话量增加了约8倍,记忆力和逻辑能力,文采都有不小的提升。基本是将下边设计 ChatGLM-6B 的字符修改为 ChatGLM2-6B 即可。
- ChatGLM-6B 系列文章之一:使用 CPU 本地安装部署运行 ChatGLM-6B 获得自己的专属 AI 猫娘
- ChatGLM-6B 系列文章之二:本地安装部署运行 ChatGLM-6B 的常见问题以及后续优化
- 其他AI相关:其他AI相关
[toc]
一些前言
当初这个模型一发布,我就第一时间尝试了,不过我虽然有3080,可惜是10GB显存版,INT4 量化级别下虽然能跑,但是智障程度有点过,还是希望能够使用全量模型,所以当时简单尝试 INT4 后就放到一边,专心折腾更聪明的openAI去了,然后月初就被 openAI 分手了(把我成功扣费了1次的信用卡在4月计费期给我先扣款再退款拒卡了!)没办法又回来找前女友 ChatGLM-6B 了,
然后在深入研究了一下后发现:我完全可以用 CPU 跑模型啊!。用 CPU 跑无非是慢一点,但无论如何也不会像用GPU跑的那样会爆显存,也不会像 chatgpt 那样因为网络或配额问题而出错,也不需要额外掏钱购买更贵的中转API或者花20刀购买plus呀。
部署过程
硬件与软件准备
- 随便一个CPU(差不多就行,毕竟我看网友还有用赛扬N6210这种东西跑的)
- 至少32GB的内存(因为模型运行大概需要23~25GB内存)
- 大于30GB硬盘可用空间
- 最好有SSD(最开始要将模型读到内存中,模型本体大概就需要占用11GB内存,使用HDD会经历一个漫长的启动过程)
- 最好有个魔法上网工具,毕竟大部分代码与模型都在github和huggingface上。
- 如果你的魔法上网工具有类似TUN模式,VPN模式直接开启就好。
- 如果你的魔法上网工具只给你了一个本地代理地址,比如127.0.0.1:1080,可以安装一个叫做“Proxifier”的软件,在Proxy Server内添加127.0.0.1:1080,在Proxification Rules内添加
一个新条目,Applications写python.exe;git-*.exe;git.exe; headless-git.exe;,Action选刚才设置的Proxy XXXX 127.0.0.1
正式开始部署
安装 Python 3.10.6 与 pip
其实3.8以上的就行,不过为了方便同时用stable-diffusion-webui,我选择了3.10.6这个版本
我这里采用直接系统内安装Python 3.10.6的方式
如果你会用Miniconda,也可以用Miniconda实现Python多版本切换,具体可以自己百度谷歌解决。
- 访问 Python3.10.6 下载页面
- 把页面拉到底,找到【Windows installer (64-bit)】点击下载
-
安装是注意,到这一步,需要如下图这样勾选 Add Python to PATH
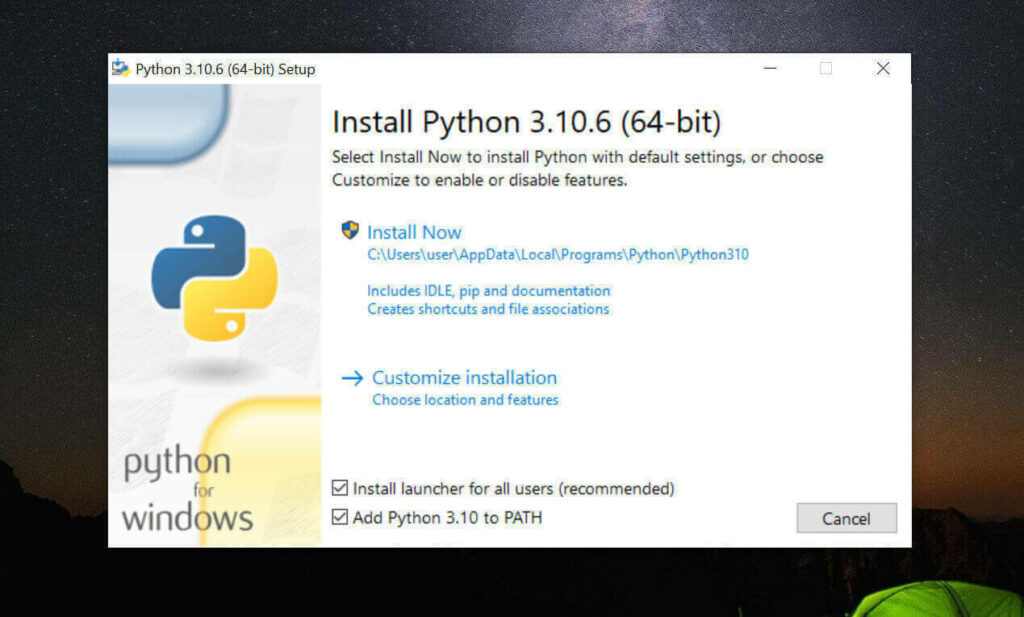
然后再点上边的 Install Now
python -
安装完成后,命令行里输入
Python -V,如果返回Python 3.10.6那就是成功安装了。 -
命令行里输入
python -m pip install --upgrade pip安装升级pip到最新版。
安装 Git
-
访问 Git 下载页面
-
点击【Download for Windows】,【64-bit Git for Windows Setup】点击下载
-
一路下一步安装
-
命令行运行
git --version,返回git version 2.XX.0.windows.1就是安装成功了。
安装 Git Large File Storage
-
点击 git-lfs.github.com 并单击“Dowdload”。
-
在计算机上,找到下载的文件。
-
双击文件 git-lfs-windows-3.X.X.exe , 打开此文件时,Windows 将运行安装程序向导以安装 Git LFS。
-
命令行运行
git lfs install,返回Git LFS initialized.就是安装成功了。
下载 ChatGLM-6B
找一个你喜欢的目录,在资源管理器,地址栏里敲CMD,敲回车,启动命令提示行窗口,输入以下命令
# 下载项目源代码
git clone https://github.com/THUDM/ChatGLM-6B
# 切换到项目根目录
cd ChatGLM-6B
# 安装依赖
pip install -r requirements.txt
# 安装web依赖
pip install gradio
- 他会在你选择的目录下生成 ChatGLM-6B 文件夹,放项目
- 这东西本体+模型大概需要25GB空间
- 整个路径中,不要有中文(比如“C:\AI对话工具\”),也不要有空格(比如“C:\Program Files”)可以避免很多奇怪的问题。
- 如果你对自己的网络稳定性非常信任,可以跳过下一步的下载模型的步骤
下载模型
还在刚才 ChatGLM-6B 目录下,在资源管理器,地址栏里敲CMD,敲回车,启动命令提示行窗口,输入以下命令
#下载模型
git clone https://huggingface.co/THUDM/chatglm-6b
然后你应该需要下载十几个GB的东西,请注意你的网络流量哦,只要他没明确提示,那就是还在下载,请不要关闭那个黑乎乎的CMD窗口,毕竟十几个G,需要下很久。
如果你实在网络不太行,可以将最后那一条下载模型部分命令替换为
# 下载模型实现
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b
然后从这里手动下载模型参数文件,并将下载的文件替换到刚才新建的chatglm-6b 文件夹内(注意这个文件夹最后是小b结尾)
修改为 CPU 运行 ChatGLM-6B
重新回到ChatGLM-6B目录下,复制一份web_demo.py文件,重名为web.py
将开头第5和第6行代码
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
修改为
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).float()
model = model.eval()
- 改了模型的存放路径:删除了
THUDM/这个第5和第6行都要改。(这个修改只有执行了上一步下载模型的人需要,如果你没执行下载模型那一步,不要改) - 从用cuda运行改为了用CPU运行:第6行最后的
.half().cuda()改为.float()(从用GPU的cuda改成用CPU运行) - 如果未来代码变动,或者你想改cli启动的那个文件的话,可以参照上文改。
运行 ChatGLM-6B
重新回到 chatglm-6B 文件夹(注意是程序的,不是放模型的那个文件夹)在资源管理器,地址栏里敲CMD,敲回车,启动命令提示行窗口,输入以下命令
python web.py
程序会运行一个 Web Server,并输出地址(应该是 127.0.0.1:7860 )。在浏览器中打开输出的地址即可使用。
调教成魅魔或者猫娘
想什么呢,我这么正经的人怎么会教你这种东西呢(逃)
安装使用常见问题及优化
如果你自身硬件性能不足,想要租用GPU机器,可以看一下这篇文章的这部分《常见云 GPU 服务介绍》

xuzeshui
2024-07-23 14:11
pip install -r requirements.txt有卡在这一步的吗,这个依赖总是装不上,等待很久之后报错error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [14 lines of output]
error: Multiple top-level packages discovered in a flat-layout: [‘csrc’, ‘vllm’, ‘cmake’].
To avoid accidental inclusion of unwanted files or directories,setuptools will not proceed with this build.
If you are trying to create a single distribution with multiple packages
on purpose, you should not rely on automatic discovery.
Instead, consider the following options:
GoodBoyboy
2024-01-24 20:41
怎么能缺少喜闻乐见的调教环节!!!
感觉ChatGLM的安全限制还是蛮难绕过的,而且容易反复触发,之前好不容易调教的稍微有点味道了突然就触发安全限制出戏了(doge)
去年夏天
2024-01-25 10:45
一般策略就是:
1. 第一句说点无关的,然后第二句再塞人设。
2. 将可能触发限制的词放前边,后面填充足够多无风险内容。
finley233
2023-07-09 21:02
E:\some\ChatGLM-6B>python web.py
Explicitly passing a
revisionis encouraged when loading a model with custom code to ensure no maliciouscode has been contributed in a newer revision.
Explicitly passing a
revisionis encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.Explicitly passing a
revisionis encouraged when loading a model with custom code to ensure no maliciouscode has been contributed in a newer revision.
Loading checkpoint shards: 100%|████████████████████████████████████████████| 8/8 [00:43<00:00, 5.39s/it]
Traceback (most recent call last):
File “E:\some\ChatGLM-6B\web.py”, line 7, in
model = model.eval()
AttributeError: ‘function’ object has no attribute ‘eval’
user01
2023-07-05 17:39
我超,最重点的调教猫娘过程居然没有
去年夏天
2023-07-06 08:48
网络上通用的那些模版都是可以用的。
蓝
2023-06-03 14:43
Internal: D:\a\sentencepiece\sentencepiece\src\sentencepiece_processor.cc(1102) [model_proto->ParseFromArray(serialized.data(), serialized.size())]
请问这个错怎么解决呀??
Michael
2023-09-20 15:21
你的模型文件有问题,或者升级sentencepiece 的版本
Anachico
2023-04-20 23:39
打扰楼主,请问运行.py文件的时候报错 OSError: [WinError 193] %1 不是有效的 Win32 应用程序。 应该怎么解决呀?前面的步骤都是正常运行的,就卡在这里了……
去年夏天
2023-04-21 08:52
是在最后一步运行 ChatGLM-6B时吗?
原因大概是因为python是64位的版本,但装的组件是32位的版本;或者组件是64位的版本,python装了32位的版本。
Anachico
2023-04-21 19:49
感谢解答!!重装了一下python成功运行!
Tim
2023-04-20 17:55
您好,请问使用CPU跑模型时, web.py里面的如下配置,是使用了INT8,还是INT4? 我想只使用INT4 ,请问怎样添加参数?
model = AutoModel.from_pretrained(“chatglm-6b”, trust_remote_code=True).float()
Tim
2023-04-21 01:21
我这个问题,问得不太好。需要说明的是:我用的是mac m2。
已经参考https://github.com/THUDM/ChatGLM-6B 的 章节“Mac 上的 GPU 加速”,配置好了。
依然很感谢楼主的这篇文章。
lee会长
2023-04-18 21:13
盟主,这个可以用于公司里用的吗? 公司内部用, 可以提供公司资料自行学习的吗?
去年夏天
2023-04-18 21:59
ChatGLM-6B项目代码依照 Apache-2.0 协议开源,ChatGLM-6B 模型的权重的使用则需要遵循 Model License。
lee会长
2023-04-18 23:19
根据本许可的条款和条件,许可方特此授予您非排他性、全球性、不可转让、不可再许可、可撤销、免版税的版权许可,允许您仅将本软件用于您的非商业研究目的.
公司内部用的话, 属于商业行为吗 ?
wikeeyang
2023-04-13 17:18
多谢楼主不厌其烦的指导!我刚也已经解决了,重新安装了本机显卡CUDA版本能用的Torch,装载参数.quantize(4)缩减的量化模型,
model = AutoModel.from_pretrained(“chatglm-6b”, trust_remote_code=True).half().quantize(4).cuda()
能用上GPU,CPU资源消耗就少很多,跑起来也还比较顺!清华这个版本不错!感谢楼主推荐分享!
我显卡NVIDIA CUDA 11.7,按如下命令行重新安装了Torch,
pip install torch2.0.0+cu117 torchvision0.15.1+cu117 torchaudio2.0.1 –extra-index-url https://download.pytorch.org/whl/cu117
再次感谢楼主悉心指导!
去年夏天
2023-04-13 17:22
不用谢,互相探讨进步吧
wikeeyang
2023-04-13 14:07
一步一步按照楼主指令做下来,安装竟然没成功。。。报错No module named ‘transformers_modules.THUDM/chatglm-6b’
去年夏天
2023-04-13 14:09
你看一眼你模型放在那里?是/ChatGLM-6B/THUDM/chatglm-6b吗?
wikeeyang
2023-04-13 14:35
是啊,我装的Python是3.11,跟3.10并列都在C:根目录下,但PATH中配置用的是3.11,所以,检查了一下,pip安装的依赖项,也都在C:\Python311目录下,git是最新的2.4 x64,其它都是按照楼主教程装的。pip在安装依赖项的时候,也看到transformers有安装,估计是不是要改一下啥配置?ChatGLM-6B我放在D:根目录下。
去年夏天
2023-04-13 14:39
把chatglm-6b文件夹复制出来,放到ChatGLM-6B目录下,变成/ChatGLM-6B/chatglm-6b的结构,然后把web.py
里第5和第6行的THUDM/chatglm-6b都改成chatglm-6b,再试试。
wikeeyang
2023-04-13 15:29
谢谢楼主指导!把目录挪出来好像是可以加载模型了,我的笔记本32GB内存,而NVIDIA显存是6GB,所以加了参数.quantize(4),以INT4的4-Bit量化加载,
model = AutoModel.from_pretrained(“chatglm-6b”, trust_remote_code=True).quantize(4).half().cuda()
但后面还是报错:
File “C:\Python311\Lib\site-packages\torch\cuda__init__.py”, line 239, in _lazy_init
raise AssertionError(“Torch not compiled with CUDA enabled”)
AssertionError: Torch not compiled with CUDA enabled
我的CUDA跟楼主一样,是11.7.1,前两天安装Stable Diffusion WebUI时候装的。
换成纯CPU运行试试:
model = AutoModel.from_pretrained(“chatglm-6b”, trust_remote_code=True).float()
结果执行后还是报内存不足,估计可能是我开了Android子系统和Linux子系统的缘故。
RuntimeError: [enforce fail at ..\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 268435456 bytes.
去年夏天
2023-04-13 15:52
GPU报错可以这样解决
先执行命令:
如果返回的是False,说明安装的PyTorch不支持CUDA,是仅支持CPU的,需要执行了下面的命令安装支持cuda的版本:
内存不足这个,按官方的说法也可以通过加载量化模型解决
1. 将加载模型改为
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()2. 安装 TDM-GCC 并在安装时勾选安装 openmp